解读 Efficient Uncertainty-aware Decision-making for Automated Driving Using Guided Branching
[toc]
本文是香港科技大学的研究结果,发表于 ICRA 2020。
作为一个自动驾驶的研发人员,通篇读下来认为这篇论文研究在实际工程应用中价值比较低。如果非学术原因,不建议深度研究。
其一,文章的亮点是自车策略选择,现在比较成熟的技术路线是 spatial-temporal planner 方案;
其二,原本吸引我的 POMDP 和 多物体交互,在文章中却被略写,没有深度。周围车辆的意图是受到自车未来行为决策影响的,所以存在一定的不确定性,如何评估这部分不确定性,如何判断对方车是否有合作意图,这部分难点问题也没有深入研究。
因为后续的精力有限,自己不会再对阅读的论文进行整理,但是我会逐渐整理并分享一个自动驾驶进阶学习资料。
Abstract
In this paper, we present an efficient uncertainty-aware decision-making (EUDM) framework, which generates long-term lateral and longitudinal behaviors in complex driving environments in real-time.
本文从纵向和横向两个维度规划自动驾驶未来 8s 的决策,优点在于决策的生成实时性。
The computation complexity is controlled to an appropriate level by two novel techniques, namely, the domain-specific closed-loop policy tree (DCP-Tree) structure and conditional focused branching (CFB) mechanism.
The key idea is utilizing domain-specific expert knowledge to guide the branching in both action and intention space.
基于领域专业知识和经验,在行为和意图空间中引导和限制自车行为扩展 (branching)。
We also release the code of our framework to accommodate benchmarking.
https://github.com/HKUST-Aerial-Robotics/eudm_planner 现在可以访问,但是目前代码没有继续维护,参考意义不大,可以作为其他算法的比较基准。
INTRODUCTION
Reasoning about hidden intentions of other agents is the key capability for a safe and robust automated driving system. However, even given perfect perception, it is still challenging to make safe and efficient decisions due to uncertain and sometimes unpredictable intentions of other agents.
自动驾驶研究领域的核心难点之一 — 推理其他交通参与者的意图。这一部分的不确定性一方面是车辆行为不确定,另一方面车辆的行为受自车行为影响,存在不确定性。
Note:自动驾驶的不确定性是客观存在的,无法彻底消除,但是可以尽量限制不确定性。这一部分的不确定性如果在上游不能解决,在行为决策层就需要对多种意图考虑 (decision-making under uncertainty),导致自车行为保守。
Partially observable Markov decision process (POMDP) provides a general and principled mathematical framework for planning in partially observable stochastic environments. However, due to the curse of dimensionality, POMDP quickly becomes computationally intractable when the problem size scales.
POMDP 知识,希望大家花时间详细了解一下,这是除 ML / RL 方法外,处理交互的一种做法。
算法实现
In this paper, we present an efficient uncertainty-aware decision-making (EUDM) framework.
First, EUDM uses a domain-specific closed-loop policy tree (DCP-Tree) to construct a semantic-level action space. Each node in the policy tree is a finite-horizon semantic behavior of the ego vehicle.
第一步:DCP-Tree 可以确定自车的初步决策,那么可以确定下来自车的行为空间。注意,其他车辆的意图还不确定。
EUDM uses the conditional focused branching (CFB) mechanism to pick out the potentially risky scenarios using open-loop safety assessment conditioning on the ego action sequence.
第二步:CFB 可以基于自车的初步决策,识别并过滤其他车辆的危险场景。
EUDM is highly parallelizable, and can produce long-term (up to 8 s) lateral and longitudinal fine-grained behavior plans in real-time (20 Hz).
规划时常是 8s,计算性能表现为 50ms,这组参数基本满足驾驶需求。
RELATED WORK
POMDP is a powerful tool to handle various uncertainties in the driving task using a general probabilistic framework. However, due to the curse of dimensionality, POMDP quickly becomes computationally intractable when the problem size scales.
POMDP 理论在不确定性决策中广泛应用,但是存在计算复杂度大的缺陷。
Hubmann et al. proposed POMDP-based decision-making methods for urban intersection and merging scenarios.
TODO: 后续可以研究一下这篇论文。
In this paper, we follow the idea of semantic-level closed-loop policies from MPDM. However, there are two major differences.
本文是在已有研究基础上 (MPDM),发现研究的缺陷,提出两个改进做法,属于对已有工作的创新。
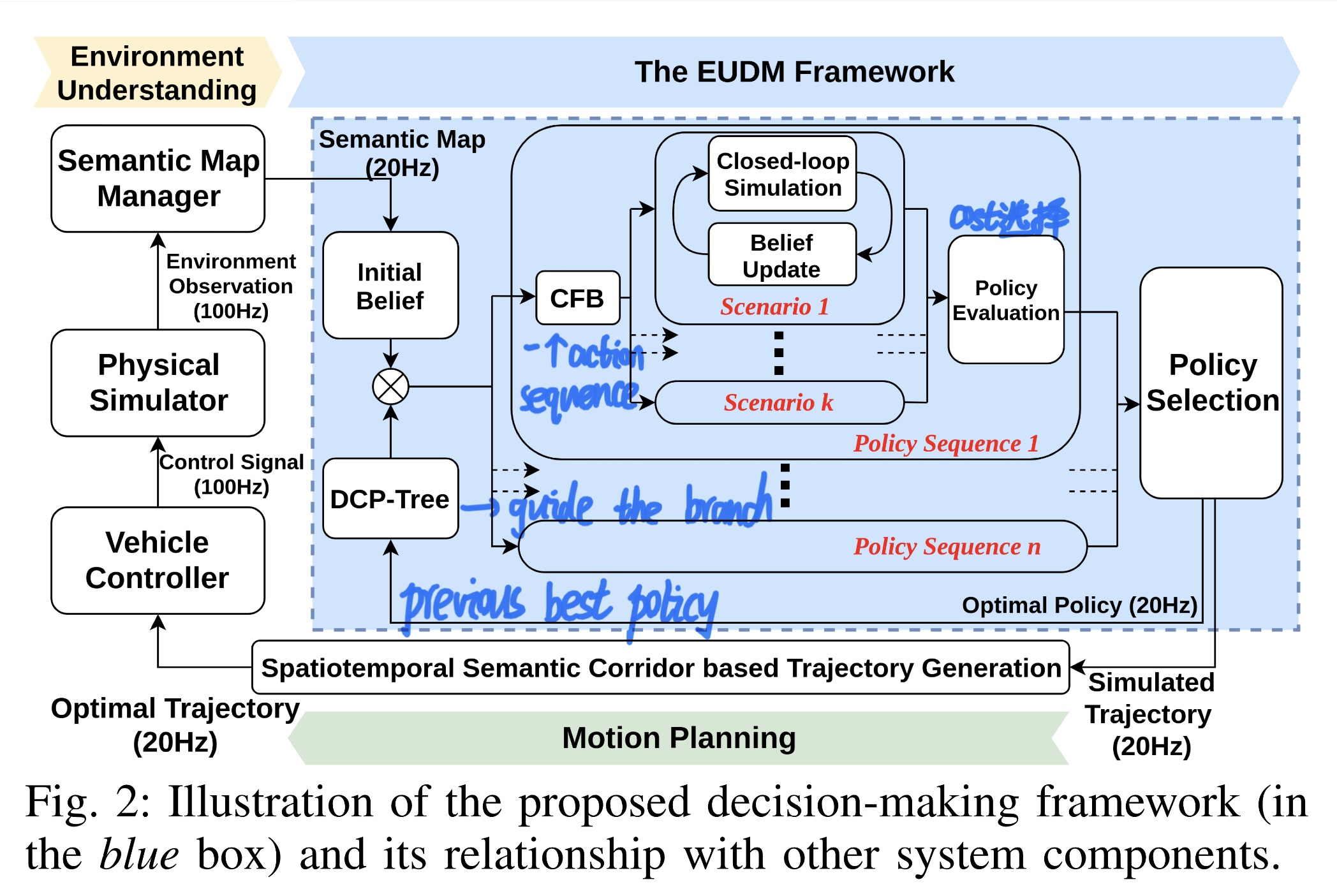
SYSTEM OVERVIEW
In EUDM, DCP-Tree is used to guide the branching in the action domain and update the semantic-level policy tree based on the previous best policy.
For each ego action sequence, the CFB mechanism is applied to pick out risky hidden intentions of nearby vehicles and achieves guided branching in intention space.
The output of the CFB process is a set of scenarios containing different hidden intentions combinations of nearby vehicles.
TODO: 附上示意图
DECISION-MAKING VIA GUIDED BRANCHING
The key feature of MPDM is using semantic-level policies instead of traditional “state”-level actions (e.g., discretized accelerations or velocities).
- one major limitation of MPDM is that the semantic-level policy of
the ego vehicle is not allowed to change in the planning horizon.
- As a result, the decision of MPDM tends to be local and may not be suitable for long-term decision-making
用车辆语意信息来描述车辆未来行为,比如跟随前方车辆,让行横向车辆等,这要比单纯的车辆状态要好用,容易理解。
Preliminaries on POMDP

The optimal policy is often pursued using a multi-step look-ahead search starting from the current belief.
POMDP 可以扩展,但是非常容易陷入爆炸问题中。
State-of-the-art online POMDP planners use Monte-Carlo sampling to deal with the Curse of Dimensionality and Curse of History. Meanwhile, generic heuristic searches such as branch-and-bound and reachability analysis can be used to accelerate the search.
Domain-specific Closed-loop Policy Tree (DCP-Tree)
以论文图 4 为例,讲解 DCP-Tree 的步骤:
The nodes of DCP-Tree are pre-defined semantic-level actions associated with a certain time duration.
The directed edges of the tree represent the execution order in time.
DCP-Tree origins from an ongoing action a, which is the executing semantic-level action from the best policy in the last planning cycle.
DCP-Tree is expanded by a pre-defined strategy: from the ongoing action, each policy sequence will contain at most one change of action in one planning cycle.
- Results: Compared to MPDM, DCP-Tree has much larger decision space resulting in more flexible maneuvers.
Conditional Focused Branching (CFB)
- 其他研究的缺陷: In the case of MPDM, the intention of the nearby vehicles is fixed for the whole planning horizon, and the initial intention is sampled according to a behavior prediction algorithm. The limitation of MPDM is that, with a limited number of samples, influential risky outcomes may not be rolled out, especially when the initial intention prediction is inaccurate.
- 本文改进:As a result, by conditioning on the ego policy sequence,
we can pick out a set of relevant vehicles w.r.t. the ego future
actions. The selection process is currently based on rule-based expert
knowledge as detailed in Sec. V.
- Instead of enumerating all the possible intentions for this subset
of vehicles, we introduce a preliminary safety check to pick out the
vehicles to which we should pay special attention.
- As a result, the branching in intention space is guided to potentially risky scenarios.
- And for the vehicles which pass the assessment, we use maximum a posteriori (MAP) from initial belief.
- 即,通过对物体的所有意图仿真,筛选出来危险的场景,然后重点关注。
- Instead of enumerating all the possible intentions for this subset
of vehicles, we introduce a preliminary safety check to pick out the
vehicles to which we should pay special attention.
NOTE:辅助算法流程,方便理清楚算法实现,这就是一个 ST Planner 的简化版本,新意不足,核心内容避而不谈。
IMPLEMENTATION DETAILS
Semantic-level Actions
- We consider both lateral and longitudinal actions to ensure the diversity of the driving policy.
- The depth of the DCP-Tree is set as 4, thereby we obtain a planning
horizon up to 8 s.
- 8s 的规划周期,满足大家的基本做法。
Forward Simulation
- The goal of the closed-loop simulation is to push the state of the
multi-agent system forward while considering the potential interaction.
- 如何考虑,如何实现,文章没有展开讨论,这恰恰是当前实践的难点内容。
- We adopt the intelligent driving model and pure pursuit controller
as the longitudinal and lateral simulation models, respectively.
- 后续做研究,可以基于此模型
Belief Update
- The belief over these intentions of agent vehicles are updated
during the forward simulation as shown in Fig. 2.
- 如何考虑,如何实现,文章没有展开讨论,这恰恰是当前实践的难点内容。
- In this work, we adopt a rule-based lightweight belief tracking
module that takes a set of features and metrics including velocity
difference, distance w.r.t. the leading and following agents on the
current and neighboring lanes, responsibility-sensitive safety (RSS),
and lane-changing model as input2. The belief tracker generates a
probability distribution over the intentions (i.e., LK, LCL, LCR).
- TODO: 看源码理解一下,这是自己关心的内容。
- Currently, we are exploring using learning-based belief trackers for
intention tracking which will be incorporated into the EUDM framework.
- 学习研究画大饼的做法,大概率没有后续进展。
CFB Mechanism
- The first step of CFB is the key vehicle selection.
- The second step is uncertain vehicle selection according to the
initial belief.
- Specifically, we pick out the vehicles, whose probabilities for the
three intentions are close to each other, as uncertain vehicles.
- three intentions 是指 {LK, LCL, LCR}.
- Note that for the vehicles with confident prediction, we select the MAP intention and marginalize the intention probabilities using the MAP selection result.
- Specifically, we pick out the vehicles, whose probabilities for the
three intentions are close to each other, as uncertain vehicles.
- The third step is using the open-loop forward simulation for safety
assessment.
- For the vehicles which fail the assessment, we enumerate all the possible combinations of their intentions. Each combination becomes a CFB-selected scenario and the probability of scenario is calculated.
- The fourth step is picking out top k scenarios according to user-preference, and we further marginalize the probabilities among the top-k scenarios.
Policy Evaluation
- The overall reward for a policy sequence is calculated by the
weighted summation of the reward for each CFB-selected scenario.
- The reward function consists of a linear combination of multiple user-defined metrics including efficiency (measured by the difference between current velocity and desired velocity), safety (measured by the distance between our vehicle and surrounding vehicles) and consistency (measured by the difference between the last best policy and the policy to be evaluated).
- 难道所有的问题,都要化解为一个优化问题吗?策略的一致性,我们一般没有考虑到,这也是一个重要的维度。
Trajectory Generation
- The behavior plan is fed to the motion planner proposed in our previous work, which utilizes a spatio-temporal corridor structure to generate safe and dynamically feasible trajectories.

EXPERIMENTAL RESULTS
Simulation Platform and Environment
- The experiment is conducted in an interactive multi-agent simulation platform as introduced in Sect.III. All agents can interact with each other without knowing the driving model of other vehicles.
Qualitative Results
Metrics
- We introduce three major metrics to evaluate the performance of two
methods, namely, safety, efficiency, and comfort.
- The efficiency is represented by the average velocity of the ego vehicle.