手把手搭建业务规则引擎 (Rule Engine)
[toc]
需求描述
作为开发人员,随着业务逻辑和功能需求的不断增加,我们经常需要维护一系列 IF…THEN…ELSE 或者 select-case 的业务逻辑 (business rules)。这部分业务规则的不断扩充,会使得代码越来越凌乱和难以维护,逐渐变成开发人员的噩梦。
举个简单的例子来感受下程序员在面对繁杂规则下的无奈。
小王家的奶牛场新进一批次奶牛,有白奶牛,黑奶牛和斑点奶牛。小王邀请你写一段程序模块,预测下各种品种的奶牛喜欢到哪块地里吃草。我们这里假设奶牛的行为受到阳光,风,草品的影响。
1 | Location moves_to(cow, env) { |
上面是一段示例代码,可以看出来在只有 3 个变量(牛奶品种,阳光,风)的情况下,我们就需要写几十行的代码来实现功能。可以想象一下,在影响变量比较多的时候,业务逻辑和应用程序如果混在一起开发的话,那么开发者需要维护上百条甚至更多的 IF-statements 才可以应付。对开发人员而言,一方面这些代码没有技术含量,开发人员积极性差,另一方面频繁变更的业务需求也会带来维护,调试和测试成本的指数级增加。比如,为了找出一个业务逻辑中的问题,开发人员往往不得不遍历混在代码各处的 IF-statements 语句,效率低下且十分痛苦。
数以千计的业务逻辑在现实中非常常见,从广告推送,跑腿外卖到火箭发射等应用中,都有数不清的业务逻辑代码,我们可以把这部分需求归结为以下几方面。
- 市场需求,业务变更是不可避免的,通常伴随着业务规则会逐渐扩充,在产品后期会变的异常复杂,同时管理层对开发效率不会妥协。
- 市场要求,业务规则经常发生变化,系统必须能够依据业务规则的变化快速、低成本的更新。
- 程序 = 算法 + 数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型,甚至有些业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化。
那么,问题来了,我们如何在大规模软件开发中,很好地维护数以千计的业务逻辑 (IF-statements) 呢?
问题建模
我们首先把这类 IF-statements 问题进行特征提取和建模,看看这类问题有什么特点呢?
- 业务决策 (decision) 受多个影响因素 (factor) 的影响;
- 业务决策和影响因素的关系是已知的,也就是说在影响因素状态确定的情况下,业务决策是唯一的。
1 | decision = rule(factor1, factor2, …, factorn) |
- 业务决策是前向的 (foreward-chaining),不可逆。决策是基于规则来推导出来的,中间可能存在多个临时特征 (feature),但是不支持从决策来推导特征和影响因素的状态。
- 用户往往只关心最终的决策,而不太在意从影响因素到决策的具体推理过程。假如我们将业务决策逻辑从系统逻辑中抽离出来,而只保留最后的决策接口给用户,并不会影响系统的正常运行和用户体验。
在调研中,规则引擎 (rule engine) 和 有限状态机 (finite state machine) 很快就能进入你的思路。这两种做法能够很好地解决上述问题,可以从一系列的影响因素或者特征中,经过已有的规则运算,得到最终的决策。同时,这两种做法支持业务决策逻辑从系统逻辑中抽离 (decoupling) 出来,使两种逻辑可以独立于彼此而变化,可以明显降低维护成本,同时支持业务逻辑的快速更新。
规则引擎 vs 有限状态机
规则引擎 和 有限状态机 的详细概念,大家可以点击链接自行阅读和理解。
规则引擎
规则引擎是一种推理引擎,它是根据已有的事实 (变量),从规则库中匹配规则,处理存在冲突的规则,执行最后筛选通过的规则。
简而言之,可以理解为是把原本杂乱不堪的 IF-statements 拆成 N 条带优先级的 "if 前提语句 then 实施语句" 的句式。
1 | # 业务逻辑 |
规则引擎通常主要使用 foreward-chaining 的 Rete 引擎,按优先级匹配条件语句,实施规则语句。规则实施后会触发事实的变化,引擎又会重新进行条件匹配,直到不能再匹配为止,Rete 算法从理论上保证了服从的最高。
有限状态机简述
通常 FSM 包含几个要素:状态管理、状态监控、状态触发、状态触发后引发的动作。这些关系的意思可以这样理解:
1 | State(S) x Event(E) -> Actions (A) -> State(S’) |
如果我们当前处于状态 S,那么发生了 E 事件, 我们应执行操作 A,状态就会转换为 S’。
规则引擎和有限状态机主要在触发条件,控制权,使用约束上不一样。
触发条件区别
在规则引擎中,上一个规则完成时会自动转移到下一个规则,而状态机则需要一个外部事件 (external event) 的触发,该事件将导致状态转移到下一个。简而言之,状态机是事件驱动型的,而规则引擎却不是。
In general, the major difference between a workflow engine and a state machine lies in focus. In a workflow engine, transition to the next step occurs when a previous action is completed, whilst a state machine needs an external event that will cause branching to the next activity. In other words, state machine is event driven and workflow engine is not.
控制权区别
规则引擎是可以预测的 (predictable)。系统可以根据我们在初始时提供的状态和规则来驱动流程 (process) 向前,规则控制着这个流程的发展。状态机恰恰相反,它是外部事件驱动着完成。即使我们已经定义好状态 (states) 和状态之间的转移条件 (transitions),决策进展 (decision making process) 也是由外部事件来决定的。虽然状态机遵循的结构仍然像工作流 (sequential workflow),但是控制权传递给了外部环境。
使用约束
如果系统不是很复杂,那么状态机是一个很好的解决方案。如果能够绘制所有可能的状态以及触发事件,则可以使用状态机。通常,状态机可以很好地用于网络协议或某些嵌入式系统。
State machine is a good solution if your system is not very complex. You may implement it if you are capable of drawing all the possible states as well as the events that will cause transitions to them. In general, state machines work well for network protocols or some of the embedded systems.
规则引擎是管理业务流程的好方法,它是任务分配,CRM 和其他复杂系统的正确解决方案。最终目标是改善业务流程和公司效率,这就是为什么它非常适合业务流程自动化的原因。
Workflow engine implementation is a good way of managing business processes. It is the right solution for task allocation, CRM and other complex systems. All in all, its ultimate goal is to improve business processes and company’s efficiency. That is why it perfectly suits for business process automation.
结合上面的分析对比,在影响因素较多,且不需要外界事件触发的情况下,使用规则引擎达到业务规则和应用的低耦合,是目前解决业务规则不断繁重的解决方案,本文后面也主要讨论规则引擎相关的问题。
规则引擎解决方案调研
在解决问题之前,最好先做充分的调研,避免重复造轮子 (Reinventing the wheel)。
规则引擎的概念最早由文章 A C++ Class for Rule-Base Objects 提出,描述了在冬季高速公路养护 (winter highway maintenance) 中的实际应用。现在看起来可能比较简单,但是放到上个世纪 90 年代,还是有新意的做法。
规则引擎的使用方法
规则引擎是一种嵌套在应用程序中的组件,它实现了将业务规则从应用程序代码中分离出来。规则引擎使用特定的语法编写业务规则,规则引擎可以接受数据输入、解释业务规则、并根据业务规则做出相应的决策。
通俗来说,规则引擎就是负责执行系统中规则的插件,亦可以作为一个远程系统供业务系统调用。
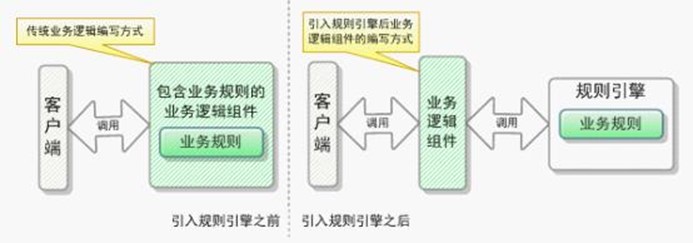
引入规则引擎后带来的好处:
- 实现业务逻辑与业务规则的分离,实现业务规则的集中管理;
- 可以动态修改业务规则,从而快速响应需求变更;
- 使业务分析人员也可以参与编辑、维护系统的业务规则;
- 使用规则引擎提供的规则编辑工具,使复杂的业务规则实现变得的简单
编程实践
规则引擎可以在系统工作时,将外部的业务规则加载到系统中,并使得系统按照该业务规则进行工作。
业务规则的制定
一个业务规则包含一组条件和满足此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。
业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。
业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。
规则引擎的功能
由于规则引擎是软件组件,所以只有开发人员才能够通过程序接口的方式来使用和控制它。
规则引擎的程序接口至少包含以下几种 API:
- 加载和卸载规则集的 API;
- 数据操作的 API;
- 引擎执行的 API。
开发人员在程序中使用规则引擎基本遵循以下 5 个典型的步骤:
- 创建规则引擎对象;
- 向引擎中加载规则集或更换规则集;
- 向引擎提交需要被规则集处理的数据对象集合;
- 命令引擎执行;
- 导出引擎执行结果,从引擎中撤出处理过的数据。
使用了规则引擎之后,许多涉及业务逻辑的程序代码基本被这五个典型步骤所取代。一个开放的业务规则引擎应该可以” 嵌入” 在应用程序的任何位置,不同位置的规则引擎可以使用不同的规则集,用于处理不同的数据对象。
现有的规则引擎
常见的开源规则引擎 – The Top 23 Rule Engine Open Source Projects
,如以下所示。

此外,你也找到一些其他开源的规则推导开源软件,比如基于规则表的推理软件 ^[2]。
本文会挑选几款教程比较多,应用范围广的规则引擎做比较和讲解。
目前,常用的商用规则管理系统 (BRMS) 是 ILOG JRules,普遍使用的开源规则引擎是 CLIPS 和 Drools。
CLIPS
根据 官方网站 介绍,CLIPS (the C Language Integrated Production System) 于 1984 年由美国航空航天局约翰逊空间中心 (NASA’s Johnson Space Center) 推出,意在克服 LISP 移植性差、开发工具和硬件成本高、嵌入性低的缺点。
Developed at NASA’s Johnson Space Center from 1985 to 1996, the C Language Integrated Production System (CLIPS) is a rule-based programming language useful for creating expert systems and other programs where a heuristic solution is easier to implement and maintain than an algorithmic solution. Written in C for portability, CLIPS can be installed and used on a wide variety of platforms. Since 1996, CLIPS has been available as public domain software.
CLIPS 是一个基于 Rete 算法 的前向推理语言,用标准 C 语言编写。它具有高移植性、高扩展性、强大的知识表达能力和编程方式以及低成本等特点。
- CLIPS 源代码
- CLIPS 官方学习文档
- 中文简介,讲述了规则引擎的工作机制。
在 C/C++ 程序中嵌入 CLIPS
基本步骤:
- 定义规则模板,规则执行阶段控制逻辑;
- 加载规则库,创建 CLIPS 执行实例;
- 将变量转换成 CLIPS 事实 (facts);
- 执行 CLIPS 规则;
- 获取 CLIPS 规则模板生成结果;
Drools
Drools 是用 Java 语言编写的开放源码规则引擎,使用 Rete 算法 对所编写的规则求值。
Drools 允许使用声明方式表达业务逻辑,可以使用非 XML 的本地语言编写规则,从而便于学习和理解。同时,通过使用其中的 DSL (Domain Specific Language),可以实现用自然语言方式来描述业务规则,使得业务分析人员也可以看懂业务规则代码。
ILOG
Ilog Jrules 是由 IBM 开发的业务规则管理系统 (Business Rules Management System,BRMS),它提供了对整个企业业务规则进行建模、编写、测试、部署和维护所必需的所有工具。
因为 Ilog Jrules 不开源,同时偏向于界面维护,这里不做详细分析和比较。
美团的实践案例
根据 从 0 到 1:构建强大且易用的规则引擎 的描述,美团点评也经历过开源 Drools 从入门到放弃的故事。
1 | 在实践中,我们发现 Drools 方案有以下几个优缺点: |
由于 Drools 的问题较多,美团点评最后放弃了 Drools,而开始基于需求模型设计一个规则引擎。
评价:在实际应用层面,重复造轮子不完全是一件坏事情,并非全无价值,例如用来回避软件许可问题、第三方模组或零件的技术限制。
重造方的轮子是重新创造一个已有的方法(重造轮子),而且其结果比已有的还差(方的轮子)。重造方的轮子是一种反模式,发生在工程师不知道或轻视标准的作法,或是不了解问题,或是不知道标准作法已可以充分地克服问题。重造方的轮子可能是经验不足的工程师所产生,或是因为第二系统效应造成。
上面的规则引擎可能千般好,但是如果我基于推理效率等考虑,就是喜欢基于业务定制开源引擎,那么应该怎么设计和实现呢?
业务定制规则引擎的优点是视图和引擎内部数据模型完全贴合业务模型,因此内部人员很容易上手;缺点是视图和引擎的设计完全基于业务模型,适用范围有限,很难低成本修改后推广到别的业务线。
基于 Rete 算法的 "前向推理" 规则引擎的设计和实现
标题比较复杂,我们来拆分一些。首先,我们实现的规则引擎只解决满足前向推理 (forward chaining) 的问题;其次,Rete 算法是解决前向推理问题的通用解法,我们使用这个算法是可以得到理论保证的,路子不会走太偏。
什么是 forward chaining
前向推理 (又叫正向推理,前向链接) 是使用推理引擎 (inference engine) 的主要方法之一,是在专家系统 (expert systems),业务和生产规则系统 (business and production rule systems) 上广泛应用的策略。
Forward chaining (or forward reasoning) is one of the two main methods of reasoning when using an inference engine and can be described logically as repeated application of modus ponens. Forward chaining is a popular implementation strategy for expert systems, business and production rule systems. The opposite of forward chaining is backward chaining.
前向推理从可用数据开始,使用推理规则来提取更多特征和数据,直到达到目的。推理引擎使用前向链接来搜索推理规则 (inference rules) 直到找到一个前提条件 (If clause) 为真;当找到这样的规则时,引擎可以得出结论或推断出结果 (Then clause),从而将新信息添加到其数据中 (可能是中间的临时特征)。推理引擎将迭代此过程,直到再无可用规则可被选用或者求得了所要求的解为止。
Forward chaining starts with the available data and uses inference rules to extract more data (from an end user, for example) until a goal is reached. An inference engine using forward chaining searches the inference rules until it finds one where the antecedent (If clause) is known to be true. When such a rule is found, the engine can conclude, or infer, the consequent (Then clause), resulting in the addition of new information to its data. Inference engines will iterate through this process until a goal is reached.
前向推理和后向推理的区别
和人类的思维相对应,规则引擎中也存在两种推理方式:正向推理 (Forward-Chaining) 和反向推理 (Backward-Chaining)。
正向推理也叫演绎法,由事实驱动,从一个初始的事实出发,不断地应用规则得出结论。首先在候选队列中选择一条规则作为启用规则进行推理,记录其结论作为下一步推理时的证据。如此重复这个过程,直到再无可用规则可被选用或者求得了所要求的解为止。
反向推理也叫归纳法,由目标驱动,首先提出某个假设,然后寻找支持该假设的证据,若所需的证据都能找到,说明原假设是正确的;若无论如何都找不到所需要的证据,则说明原假设不成立,此时需要另做新的假设。
前向推理算法
前向推理应用规则从前提 (premises) 应用到结论 (conclusions)。目前,它使用暴力算法 (brute force algorithm),随机选择来源 (source) 和规则,应用规则以得出结论,重新插入结论作为新的来源 (source),并迭代上述过程直到达到停止标准 ^[3]。
The forward chainer applies rules from premises to conclusions. It currently uses a rather brute force algorithms, select sources and rules somewhat randomly, apply these to produce conclusions, re-insert them are new sources and re-iterate till a stop criterion has been met.
Rete 算法
开源规则流引擎实践 深入剖析了基于 rete 算法的规则引擎;RETE 算法简述 & 实践 以例子来讲述 rete 算法的实践。本节基于上述两篇博客文章,经整理和消化后介绍 Rete 算法 ^[4]。
Rete 算法最初是由 CMU 的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法,该算法提供了专家系统的一个高效实现。
Rete 匹配算法是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。核心思想是将分离的匹配项根据内容动态构造匹配树,以达到显著降低计算量的效果。自 Rete 算法提出以后,它就被用到一些大型的规则系统中,像 ILog、Jess、JBoss Rules 等都是基于 RETE 算法的规则引擎。
Rete has become the basis for many popular rule engines and expert system shells, including Tibco Business Events, Newgen OmniRules, CLIPS, Jess, Drools, IBM Operational Decision Management, OPSJ, Blaze Advisor, BizTalk Rules Engine, Soar, Clara and Sparkling Logic SMARTS.
Rete 算法可以被分为两个部分:规则编译和规则执行。当 Rete 算法进行事实的断言时,包含三个阶段:匹配、选择和执行,称做 match-select-act。
1 | graph LR |
Rete 算法相关概念
- Fact:已经存在的事实,它是指对象之间及对象属性之间的多元关系。
1 | 事实用一个三元组来表示:(标识符 ^ 属性 值) |
- Rule:规则,包含条件和行为两部分,条件部分又叫左手元(LHS),行为部分又叫右手元(RHS)。条件部分可以有多条条件,并且可以用 and 或 or 连接。其一般形式如下:
1 | (name-of-this-production |
- Patten:模式,也就是规则的条件部分,是已知事实的泛化形式,是未实例化的多元关系。
- RootNode:Rete 网络的根节点,所有对象通过 Root 节点进入网络。

Rete 规则编译
Rete 规则执行
Rete 算法优点
程序开发实践
参考 ^[5]。
规则模型
规则主要由三部分构成:
-
FACT 对象:用户输入的事实对象,作为决策因子使用。
-
规则:LHS(Left Hand Side)部分即条件分支逻辑。RHS(Right Hand Side)部分即执行逻辑。
- LHS 和 RHS 部分是由一个或多个模式 (pattern) 构成的。模式是规则内最小单位。模式的输入参数可以是另一个模式或 FACT 对象(比如逻辑与运算 [参数 1] && [参数 2] 中参数 1 可以是另一个表达式)。
- 结果对象:规则处理完毕后的结果。需要支持自定义类型或者简单类型 POD。
系统模型
系统模型主要由 3 个模块构成。
- 知识库:负责提供配置视图和模式因子。知识库之所以叫 “知识” 库一个很重要的特征是知识库可以低成本扩展知识。
- 模式:构成规则的最小单位,不可拆分,可以直接被规则引擎执行。
- 资源管理器:负责管理规则。
- 依赖管理:负责将规则解析为模式树。为了最大限度地增强规则的表达能力,每一个模式设计都很 “原子” (atom),这样如果想配置一个完整语义的规则,则必须由多个子规则共同构成,因此规则之间会有树形依赖关系。
- 规则引擎:负责执行规则。
- 模式执行器:负责直接执行模式。执行器可以根据业务的表达能力需求选择基于 Drools、Aviator 等第三方引擎,甚至可以基于 ANTLR 定制。
运行实践
- 预加载规则实例。在引擎初始化阶段将规则实例缓存在本地。
- 预编译规则实例。因为规则每次编译执行会导致性能问题,因此会在引擎初始化和规则有变更这两个时机将增量版本的规则预编译成可执行代码。
系统代码调用规则引擎的基本步骤:
- 定义规则模板,规则执行阶段的控制逻辑;
- 加载规则库,创建规则引擎实例;
- 将变量转换成规则引擎的事实;
- 执行规则推理;
- 获取规则模板生成结果;
References
- [1] WORKFLOW ENGINE VS. STATE MACHINE
- [2] A Table-based Rules Engine Suite using XML
- [3] Forward Chainer
- [4] Rete Algorithm from Wikipedia
- [5] https://www.mtyun.com/library/maze-framework
- Business rules engine from Wikipedia
- Inference engine from Wikipedia
- 规则,推理机和规则引擎
- RETE 算法简述 & 实践
- 讲解的比较好
- rete 算法的 github 实现