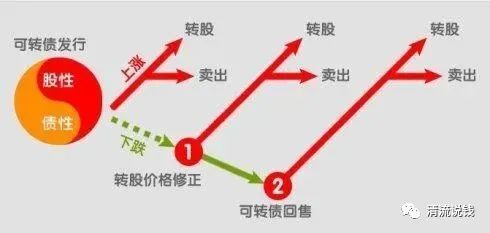
2011 年,柯普出版了《激情之夜:人和机器所作的俳句两千首》( Comes the Fiery Night: 2000 Haiku by Man and Machine),其中有一部分是安妮写的,其他则来自真正的诗人。但书中并未透露具体篇目的作者是谁。如果你认为自己一定可以看出人类创作与机器作品的差异,欢迎挑战。
It is such a general and powerful tool for combining information in the presence of uncertainty.
What is it?
You can use a Kalman filter in any place where you have uncertain information about some dynamic system, and you can make an educated guess about what the system is going to do next.
Kalman filters are ideal for systems which are continuously changing. They have the advantage that they are light on memory (they don’t need to keep any history other than the previous state), and they are very fast, making them well suited for real time problems and embedded systems.
It could be data about the amount of fluid in a tank, the temperature of a car engine, the position of a user’s finger on a touchpad, or any number of things you need to keep track of.
How a Kalman filter sees your problem
The Kalman filter assumes that both variables are random and Gaussian distributed. Each variable has a mean value 𝜇, which is the center of the random distribution (and its most likely state), and a variance 𝜎2, which is the uncertainty.
从参数之间的关联发掘更多信息:比如机器人的速度和位置,如果速度快,那么位置可能就比较远。
This kind of relationship is really important to keep track of, because it gives us more information: One measurement tells us something about what the others could be. And that’s the goal of the Kalman filter, we want to squeeze as much information from our uncertain measurements as we possibly can!
参数之间的相关性,可以用协方差矩阵 (covariance matrix) 来表示,即矩阵中的每个元素 ∑ij 表示第 i 个和第 j 个状态变量之间的相关度。注意,协方差矩阵是一个对称矩阵,这意味着可以任意交换 i 和 j。
This correlation is captured by something called a covariance matrix.
Describing the problem with matrices
We need some way to look at the current state (at time k-1) and predict the next state at time k. We can represent this prediction step with a prediction matrix, Fk.
请注意,预测矩阵要求严格反映运动的特征,要求预测准确,不能模糊。
For prediction matrix, it takes every point in our original estimate and moves it to a new predicted location, which is where the system would move if that original estimate was the right one.
不太理解这个公示是如何推导出来的,数学的理论知识不够踏实。
External influence
外部系统的影响
There might be some changes that aren’t related to the state itself — the outside world could be affecting the system.
control matrix
control vector
External uncertainty
Everything is fine if the state evolves based on its own properties. Everything is still fine if the state evolves based on external forces, so long as we know what those external forces are.
如何应对外界的不确定性,比如四旋翼控制中的风影响。
We can model the uncertainty associated with the “world” (i.e. things we aren’t keeping track of) by adding some new uncertainty after every prediction step
Every state in our original estimate could have moved to a range of states.
图片讲解
In other words, the new best estimate is a prediction made from previous best estimate, plus a correction for known external influences.
And the new uncertainty is predicted from the old uncertainty, with some additional uncertainty from the environment.
Refining the estimate with measurements
We might have several sensors which give us information about the state of our system.
Each sensor tells us something indirect about the state— in other words, the sensors operate on a state and produce a set of readings.
The units and scale of the reading might not be the same as the units and scale of the state we’re keeping track of. You might be able to guess where this is going: We’ll model the sensors with a matrix.
卡尔曼滤波的精妙处:
One thing that Kalman filters are great for is dealing with sensor noise. In other words, our sensors are at least somewhat unreliable, and every state in our original estimate might result in a range of sensor readings.
From each reading we observe, we might guess that our system was in a particular state. But because there is uncertainty, some states are more likely than others to have have produced the reading we saw.
We have two Gaussian blobs: One surrounding the mean of our transformed prediction, and one surrounding the actual sensor reading we got.
配图
We must try to reconcile our guess about the readings we’d see based on the predicted state (pink) with a different guess based on our sensor readings (green) that we actually observed.
If we have two probabilities and we want to know the chance that both are true, we just multiply them together.
The mean of this distribution is the configuration for which both estimates are most likely, and is therefore the best guess of the true configuration given all the information we have.
Combining Gaussians
Wrapping up
卡尔曼滤波用于线性系统,扩展卡尔曼滤波适用于非线性系统。
This will allow you to model any linear system accurately. For nonlinear systems, we use the extended Kalman filter, which works by simply linearizing the predictions and measurements about their mean.
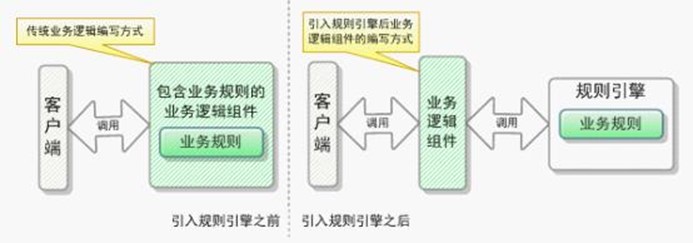
In general, the major difference between a workflow engine and a state machine lies in focus. In a workflow engine, transition to the next step occurs when a previous action is completed, whilst a state machine needs an external event that will cause branching to the next activity. In other words, state machine is event driven and workflow engine is not.
State machine is a good solution if your system is not very complex. You may implement it if you are capable of drawing all the possible states as well as the events that will cause transitions to them. In general, state machines work well for network protocols or some of the embedded systems.
Workflow engine implementation is a good way of managing business processes. It is the right solution for task allocation, CRM and other complex systems. All in all, its ultimate goal is to improve business processes and company’s efficiency. That is why it perfectly suits for business process automation.
根据 官方网站 介绍,CLIPS (the C Language Integrated Production System) 于 1984 年由美国航空航天局约翰逊空间中心 (NASA’s Johnson Space Center) 推出,意在克服 LISP 移植性差、开发工具和硬件成本高、嵌入性低的缺点。
Developed at NASA’s Johnson Space Center from 1985 to 1996, the C Language Integrated Production System (CLIPS) is a rule-based programming language useful for creating expert systems and other programs where a heuristic solution is easier to implement and maintain than an algorithmic solution. Written in C for portability, CLIPS can be installed and used on a wide variety of platforms. Since 1996, CLIPS has been available as public domain software.
CLIPS 是一个基于 Rete 算法 的前向推理语言,用标准 C 语言编写。它具有高移植性、高扩展性、强大的知识表达能力和编程方式以及低成本等特点。
前向推理 (又叫正向推理,前向链接) 是使用推理引擎 (inference engine) 的主要方法之一,是在专家系统 (expert systems),业务和生产规则系统 (business and production rule systems) 上广泛应用的策略。
Forward chaining (or forward reasoning) is one of the two main methods of reasoning when using an inference engine and can be described logically as repeated application of modus ponens. Forward chaining is a popular implementation strategy for expert systems, business and production rule systems. The opposite of forward chaining is backward chaining.
Forward chaining starts with the available data and uses inference rules to extract more data (from an end user, for example) until a goal is reached. An inference engine using forward chaining searches the inference rules until it finds one where the antecedent (If clause) is known to be true. When such a rule is found, the engine can conclude, or infer, the consequent (Then clause), resulting in the addition of new information to its data. Inference engines will iterate through this process until a goal is reached.
The forward chainer applies rules from premises to conclusions. It currently uses a rather brute force algorithms, select sources and rules somewhat randomly, apply these to produce conclusions, re-insert them are new sources and re-iterate till a stop criterion has been met.
Rete has become the basis for many popular rule engines and expert system shells, including Tibco Business Events, Newgen OmniRules, CLIPS, Jess, Drools, IBM Operational Decision Management, OPSJ, Blaze Advisor, BizTalk Rules Engine, Soar, Clara and Sparkling Logic SMARTS.